| “星火”多因子系列(十):如何对Beta因子进行稳健估计? 投资要点 ► 引言:从CAPM模型模型说起 作为最早的单因子定价系统 | 您所在的位置:网站首页 › capm beta怎么算 › “星火”多因子系列(十):如何对Beta因子进行稳健估计? 投资要点 ► 引言:从CAPM模型模型说起 作为最早的单因子定价系统 |
“星火”多因子系列(十):如何对Beta因子进行稳健估计? 投资要点 ► 引言:从CAPM模型模型说起 作为最早的单因子定价系统
|
来源:雪球App,作者: 量化陶吧,(https://xueqiu.com/8744430809/141456733) 投资要点 ► 引言:从CAPM模型模型说起 作为最早的单因子定价系统——CAPM模型认为个股预期收益之间的差别取决于其承担的系统性风险大小,而该系统性风险的大小可用Beta因子衡量。 由于Beta因子的估计本身涉及到较多参数,如何对参数进行选择才能够得到稳健的Beta估计值,业界现有的探讨却并不多见。本文我们从不同估计周期、加权方式、压缩方法三个方面出发,从实证角度介绍如何对Beta因子进行稳健估计。 ►Beta估计方式及误差衡量方式 Beta 因子的估计可以划分为等权情况下的CAPM Beta、EWMA加权情况下的 CAPM Beta 及压缩估计的 Beta方法 。 关于估计误差的衡量,本文介绍了均方根误差RMSE、平均绝对误差MAE及 Menchero (2016 )方法 。 ►实证检验 回望周期的选择:采用过去6个月和1年的日度收益率数据要明显优于1个月和3个月。 加权方式的选择:采用EWMA加权方式的Beta因子估计要优于等权方式的Beta因子估计。 先验因子的选择:采用压缩方法对Beta因子进行估计能够显著减小其预测误差,且行业均值作为先验因子效果最佳。 结论:采用过去1年的日度收益率数据,并经过EWMA加权,同时采用个股所在行业的行业均值作为先验因子进行压缩的方式,能够有效地改善Beta因子的预测能力。 ►风险提示 本报告统计数据基于历史数据,过去数据不代表未来,市场风格变化可能导致模型失效。 ►更多交流欢迎联系张宇,联系方式:17621688421 (请注明机构+姓名) 欢迎在Wind中搜索“星火“和”拾穗”多因子系列,下载阅读我们的专题报告。
作为最早的单因子定价系统——CAPM模型认为个股预期收益之间的差别取决于其承担的系统性风险大小,而该系统性风险大小可用Beta因子进行衡量。在“拾穗”系列(9)《牛市抢跑者:低Beta一定代表低风险吗?》中,我们对2019年表现优异的高Beta策略进行了分析,并得出牛市时买入高Beta资产能够轻松战胜指数的结论。然而,由于Beta因子的估计本身涉及到较多参数,如何对参数进行选择才能够得到稳健的Beta估计值,业界现有的探讨却并不多见。在本篇专题中,我们将就Beta因子计算当中的不同估计周期、加权方式、压缩方法进行比较,从实证角度介绍如何对Beta因子进行稳健估计。 引言:从CAPM模型说起 1 作为最早的单因子定价模型——资本资产定价(CAPM)模型认为个股预期收益之间的差别取决于个股承担的系统性风险,而该系统性风险的大小则可通过Beta因子进行衡量,具体表示如下:
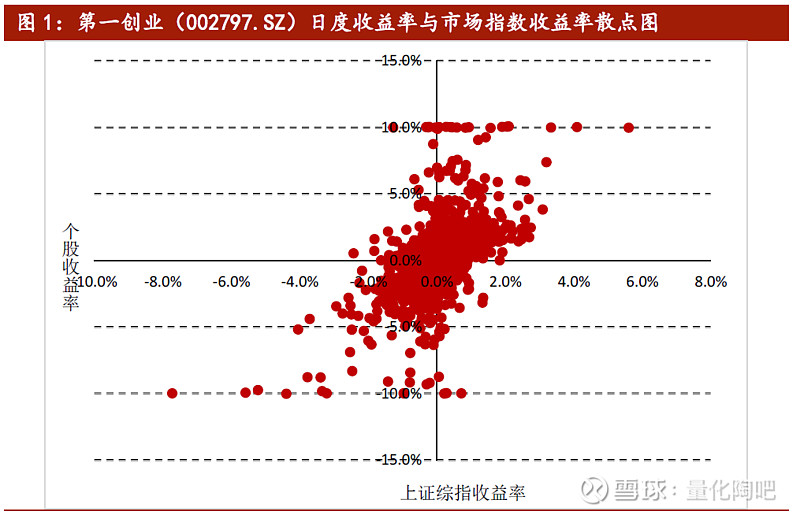
为了对如上模型有更深刻的理解,我们首先观察单只个股的收益率与市场指数收益率在时间序列上的相关关系。图1展示了第一创业(002797.SZ)在2016.5.12-2020.2.14期间,个股的日度收益与市场指数日度收益之间的散点图(该股票的Beta均值为1.80)。可以看到,该股票的日度收益与市场收益之间呈现出非常强的正相关关系,也正是由于这一相关关系的存在,使得上述根据时间序列回归计算Beta因子的方法存在其合理性。
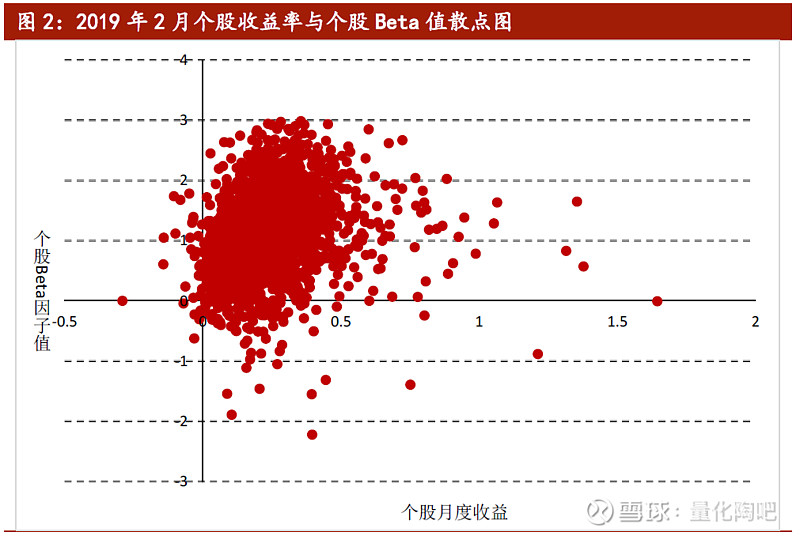
接下来我们再来观察横截面上,个股的预期收益与其Beta因子值之间的相关关系。图2展示了2019年2月全市场所有的个股Beta因子(2019.1.31因子值)与其月度收益率(2月的月度收益)之间的散点图。由于该月的市场收益为正(17.84%),因此个股收益与其Beta因子值之间呈现出明显的正相关关系。
在CAPM模型刚提出时,Beta因子衡量的是股票收益相对于市场收益的弹性。若单只股票的Beta值大于1,它表示股票波动大于市场波动,该股票的弹性较大;若Beta值小于1,它表示股票波动小于市场波动,该股票的弹性相对较小,因此传统意义上Beta因子可以被当作衡量股票风险的一个指标。 随着多因子模型的兴起,Beta因子本身也有了更为广泛的含义,它表示投资组合在风险因子上的暴露程度,衡量的是组合相对风险因子溢价的敏感度。若某个组合在Beta因子上的暴露越高,该组合在风险因子上的敞口也就越大,因而所暴露的市场风险也就越大。在本文的介绍中,我们取其狭义的Beta含义,也就是股票收益相对市场收益的波动幅度。 在美股市场中,将Beta因子作为选股因子的文献有很多,“低Beta异象”广泛存在。Baker等(2011)对美股市场进行分析发现,低Beta的股票在未来的表现要普遍优于高Beta股票,这似乎在长牛的美股市场上来说是一个令人费解的现象。Frazzini等(2014)提出BAB因子(Betting Against Beta),通过杠杆做多低Beta股票同时做空高Beta股票的Beta中性组合,从杠杆资金限制的角度来解释低Beta异象的存在。然而,在前述的“拾穗”系列(9)中同样检验了将Beta因子作为选股因子在A股市场上的表现情况,结果发现在全样本内Beta因子并不是有效的Alpha因子:在不同的市场状态下,Beta因子展现出不同方向的有效性。 本文的主要目的是介绍如何选择有效的参数对Beta进行稳健估计,因此在下文中,我们将重点关注Beta估计时的方法及参数选择(如回望时间、加权方式、压缩方法等),对于“低Beta异象”的具体研究我们将留在以后再进行探讨。 Beta因子估计方式比较 2 在上文中,我们从CAPM模型出发,对Beta因子的基本概念进行了简要介绍。事实上,我们关心的永远是个股或组合在未来一段时间的Beta值,但由于无法获取未来的数据来计算Beta,因此最为有效的方法即是根据股票过去一段时间内的交易数据计算其历史Beta值,并将其作为个股未来Beta值的近似估计。
2.1 等权方式下的CAPM Beta(CAPM Beta) 如前所述,Beta因子衡量的是个股收益相对指数收益的波动幅度,因此可以通过如下的时间序列回归对其进行估计:
其中,分子可以表示为个股日度收益与市场日度收益的协方差,而分母可以表示为市场日度收益的方差。在Python中,采用如上解析解方法对Beta因子进行计算时,可以考虑采用pd.rolling函数,从而在保证数据计算准确性的前提下大大加快Beta因子的计算时间。 2.2 EWMA方式下的CAPM Beta(EWMA Beta) 在实际计算中,由于我们采用的历史数据较长(通常长达1年甚至更久),而距离当前时间较远的日期价格信息对当前市场的影响相对较小,因此我们可以在简单历史Beta估计的基础上,对不同的时间样本点赋予不同的权重,这种方式的Beta因子估计也是Barra模型中估计的主要方式。 具体来讲,我们在采用2.1小节的方法来估计Beta因子时,不再采用普通最小二乘OLS回归(这种方法将每个样本点视为等权对待),而是采用加权最小二乘WLS回归。假设当前时间为t时刻,
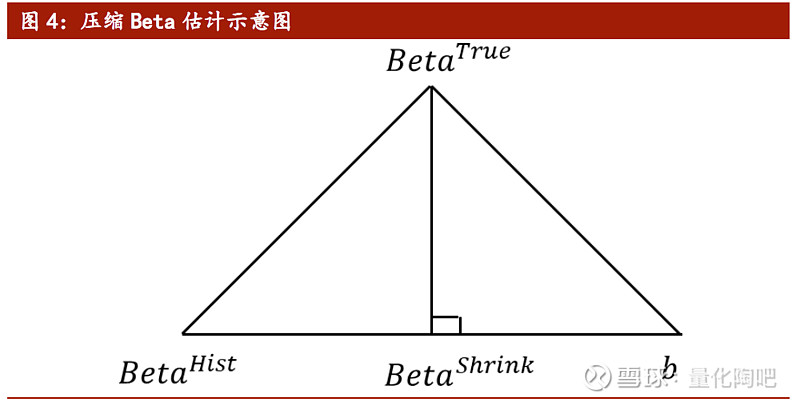
尽管可以采用WLS方法对EWMABeta进行解析解的求解,但是在Python中却并不能直接采用pd.rolling的方式对其进行向量化的计算,这在一定程度上加大了EWMA Beta估计的复杂性。这背后主要的原因在于,个股在交易过程中会存在停牌的情况,而对于停牌日的数据点权重我们需要进行逐个剔除,最终将权重进行归一化处理。由于每只股票的停牌日期并不相同,因此对于历史数据点赋予的权重也不一样,所以暂时只能采用循环的方式对其进行求解。 2.3 贝叶斯压缩Beta估计 长期关注多因子模型研究的投资者对于贝叶斯压缩调整(BayesianShrinkage)的概念应该并不陌生,在我们关于多因子风险矩阵调整和Ledoit-Wolf压缩矩阵调整的相关报告中,就多次介绍过贝叶斯压缩调整的方法(具体细节可参见“拾穗”系列(11)及“星火”系列(八)《组合风险控制:协方差矩阵估计方法介绍及比较》)。 事实上,关于Beta因子的贝叶斯压缩调整最早由Vasicek(1973)提出,它是将采用历史数据估计得到的Beta值与采用结构化估计的先验Beta进行权重组合,得到新的估计Beta。理论上而言,采用历史数据得到的Beta值是真实Beta值的无偏估计量,但是其估计方差较大;而另一方面,先验Beta是真实协方差矩阵的有偏估计量,但其估计方差较小。因此,二者的线性组合在一定程度上可以认为是在“取己之长,补彼之短”,其示意图如图4所示。
具体来讲,个股Beta因子的贝叶斯压缩调整估计可表示为:
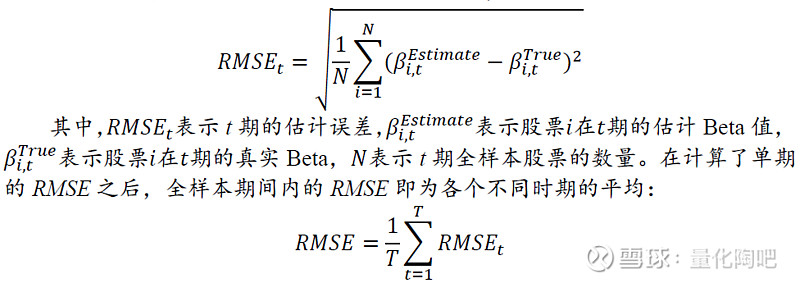
估计误差衡量方法介绍 3 到目前为止,我们已经对三种不同的Beta因子估计方法进行了介绍。在实证检验何种方式的估计效果更好之前,我们必须寻找一个行之有效的误差衡量方法。在本小节中,我们介绍统计学中常用的均方根误差(RMSE)、平均绝对误差(MAE)及Menchero(2016)提出的方法,为后续实证研究打下基础。 3.1 均方根误差RMSE 均方根误差RMSE(Root MeanSquared Error)是通过计算估计Beta与已实现Beta之间误差平方和来衡量估计误差的一种方法,RMSE的计算方式为:
3.2 平均绝对误差MAE 平均绝对误差MAE(Mean Absolute Error)是通过计算Beta与已实现Beta之间的绝对误差的平均值来衡量估计误差的一种方法,MAE的计算方式为: 3.3 Menchero(2016)方法
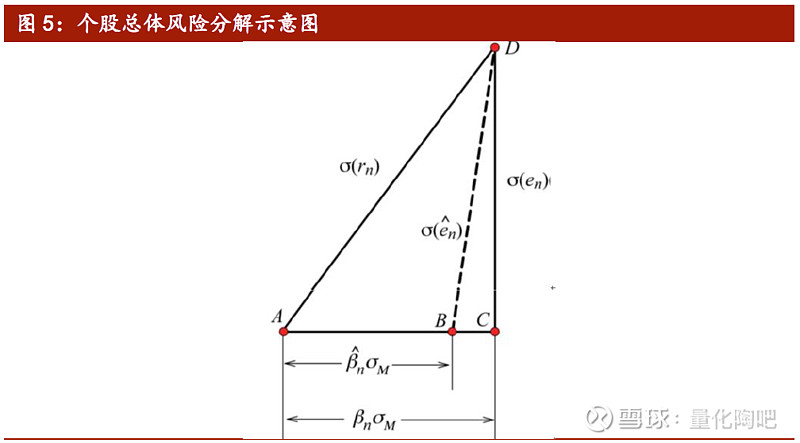
如图5所示,当我们所估计得到的Beta值小于真实的Beta时,估计得到的个股市场风险大小可用AB向量表示,由于个股整体波动仍然可用AD向量表示,因此此时估计得到的个股特质风险即为BD线条的长度。Menchero(2016)正是通过这种方式,将对Beta因子的估计误差转移为对个股特质风险估计误差的度量上。 假设现有A、B两种方法对Beta因子进行估计,那么二者之间相对Beta误差的估计可以表示为:
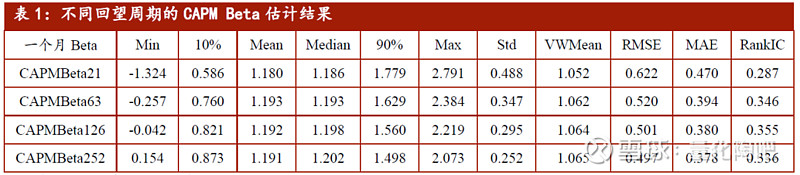
在如上分析中,A和B两种方法既可以是两种历史Beta的估计方式,也可以是估计Beta与已实现Beta。在Menchero(2016)的实证研究中,是将某一种方法视为基准,再去比较其他方法与该基准之间的相对误差。 实证检验 4 到目前为止,我们已经介绍了三种不同的Beta因子估计方法:(1)简单CAPM Beta(2)EWMA方式下的CAPM Beta(3)压缩矩阵估计下的Shrinkage Beta。并且介绍了衡量Beta估计误差的三种方式。下面,我们将从实证角度分析何种方式对于真实Beta因子的估计更为稳健。我们将从回望时间、加权方式、先验Beta的选择三个方面进行探讨,从RMSE和MAE的角度对各类估计方法进行比较。 4.1 数据说明 在进行结果展示之前,本部分首先对选取的数据进行说明。选取样本时间为2009.12.31-2020.1.23,每月月末对全体A股的Beta因子值进行估计。考虑到停牌、退市等情况会对Beta的计算产生影响,并且新股上市初期经常会存在连续涨停的情况从而在计算Beta时会偏离均值过高,因此在实证中需要做以下处理: (1) 回测时间:2009.12.31-2020.1.23; (2) 回测样本:当期Wind全A指数成分股; (3) 样本筛选:剔除上市时间少于100天、剔除调仓日停牌一天、剔除ST、*ST、PT等被标为风险预警的股票、剔除调仓日涨停或者跌停的股票; (4) 基准指数:每期满足条件的样本股的自由流通市值加权收益; (5) 计算频度:每月最后一个交易日计算一次。 尽管我们对数据进行了上述预处理,但是难免还是会存在一些异常值,比如Beta过于偏离均值的极端情况,所以在Beta的计算结果中,我们将Beta大于3(或Beta小于-3)的数据调整为3(或-3)。 在计算个股的真实Beta时,我们可以计算个股未来1个月的Beta值,也可以计算个股未来3个月的Beta值。由于公募基金量化策略的调仓频率通常以月度为主,因此我们在下文展示的是历史Beta估计值与未来1个月Beta因子值之间的误差大小。需要说明的是,无论是采用未来1个月真实Beta,还是未来3个月的真实Beta,下文报告的结论都具有稳健性。 4.2 回望周期的选择 本部分我们讨论回望周期的选择对于估计准确性的影响。以CAPM Beta估计方法为例,表1展示了采用过去1个月、3个月、6个月和1年的日度收益率数据估计得到的基本信息。在每个月月末计算得到满足条件的样本个股Beta因子值后,即可计算每期的统计量,最终报告在表1中的统计量为每期平均值(下同)。 首先,我们来观察全样本的Beta均值情况,此处分别报告简单均值(Mean)和自由流通市值平均(VWMean)两种。由于在市场指数的编制采用自由流通市值加权,因此各类Beta因子的自由流通市值加权平均(VWMean)接近于1,之所以并不恰好等于1,认为是由于部分个股存在短期停牌等原因造成的。
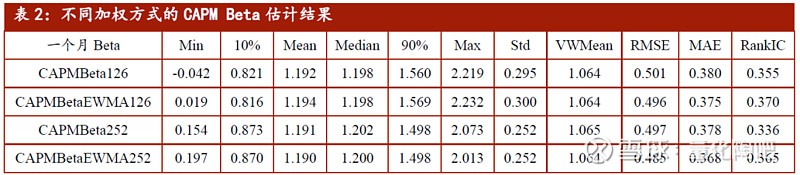
接下来,我们观察不同回望周期的选择得到的Beta因子值稳健性。由描述性统计可以看到,采用过去21天数据计算得到的Beta因子值的最小值(Min)、最大值(Max)及标准差(Std)都要显著地更高,而采用过去1年数据计算得到的Beta因子值的最小值、最大值及标准差都要更小。也就是说,数据回望的周期越长,个股计算得到的Beta因子值的差距就越小,相较而言不容易出现极端异常值。 下面,我们聚焦于关键的误差衡量指标RMSE和MAE。可以看到,回望的周期越长,估计误差将会越小。采用过去1年的数据估计得到的Beta因子将会显著地优于采用1个月数据估计得到的Beta因子。最后,表1的最后一列还计算了当期估计Beta与下期真实Beta之间的秩相关系数(RankIC)均值。可以看到,采用过去21天的数据估计得到的Beta值的效果最差(RankIC仅为0.287),而采用126天的数据计算得到的Beta值的效果最好(RankIC达到0.355)。 4.3 加权方式的选择 由4.2小节可知,最理想的回望周期为6个月或者1年的数据。接下来我们观察采用EWMA的方式,对近期的数据赋予更高的权重是否有利于Beta因子的估计。
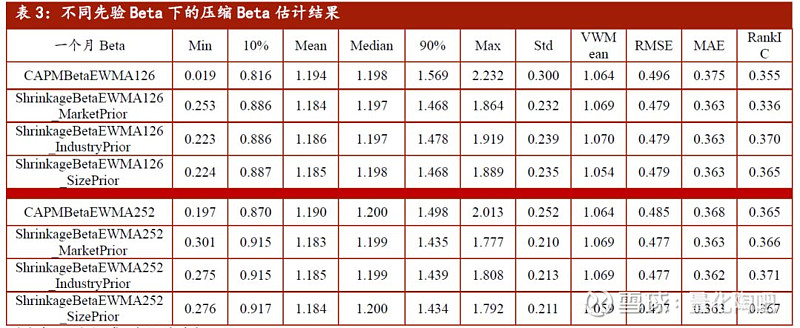
表2展示了不同的加权方式下,采用过去6个月(半衰期为3个月)和过去1年(半衰期为6个月)的数据计算得到的Beta因子的基本信息,我们重点关注最后三列。由RMSE及MAE指标可以看到,对于不同的回望周期而言,采用EWMA加权方法能够明显的降低估计误差,这说明了这种加权方式的有效性。此外,从估计Beta与真实Beta之间的RankIC也可以看出,采用加权方式估计得到的Beta因子值的预测效果更好。 4.4 压缩模型下不同先验Beta的选择 到目前为止,我们可以看到采用EWMA方式下的6个月或者1年的数据估计得到的Beta因子较为稳健。本部分,我们对压缩估计下的不同Beta因子方式选择进行探讨。前面我们提到,先验Beta的选择可以分为三类:(1)市场平均Beta(2)行业平均Beta(3)所在市值分组的市值加权平均Beta。表3对三种先验Beta方式下的压缩Beta估计进行了汇报。
可以看到,采用不同的先验Beta值进行压缩估计的方法均能够明显改善估计效果。以采用过去1年的数据为例,EWMA Beta的RMSE从0.485降至0.477,其RankIC从0.365提高至0.371,且这一结论同样适用于采用过去126天的数据估计得到的Beta因子值。 此外,在市场均值、行业均值和市值分组均值三种先验Beta的选择中,其RMSE的差别并不大,但是从RankIC的角度来讲选择行业Beta均值作为先验Beta的预测效果要普遍更好。 4.5 不同分组下的Beta估计误差 本部分,我们观察不同Beta分组下的各种不同方式的估计误差对比。在每一期我们将个股的Beta因子分为10组,随后计算每组的RMSE均值,最后将时间序列上的RMSE取平均,并绘制柱状图。
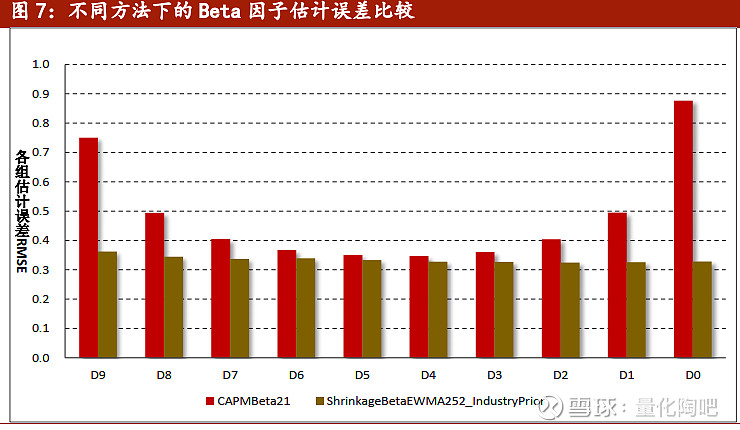
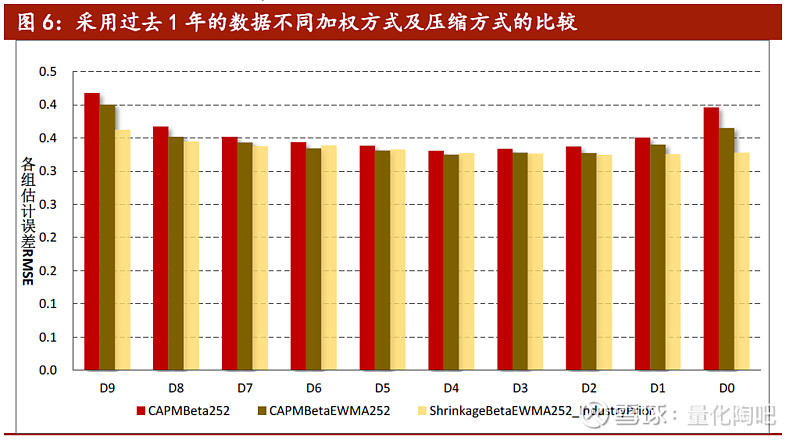
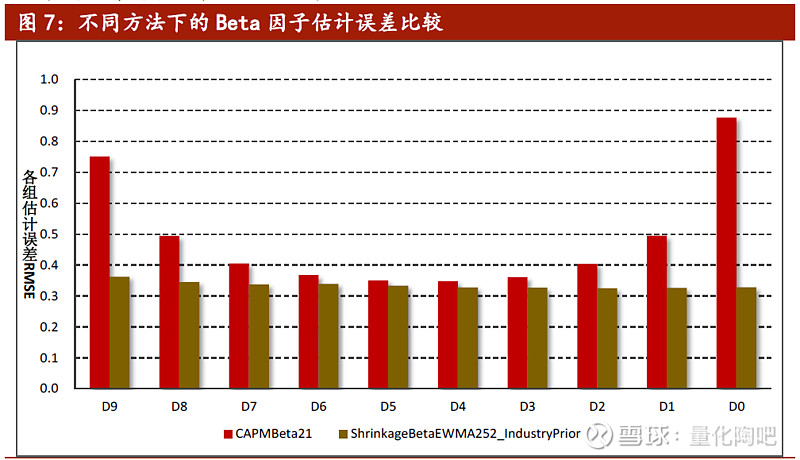
图6展示了采用过去1年的数据,通过不同加权方式和压缩方式的效果改进。可以看到,各组的估计误差都有较为稳健的改善,其中在D9组(历史Beta值最大)和D0组(历史Beta值最小)的组别效果最好。图7展示了最粗糙和最精细的两种估计方式下的误差对比,可以看到通过我们的参数选择,Beta因子估计的效果确实得到了非常明显的提升。
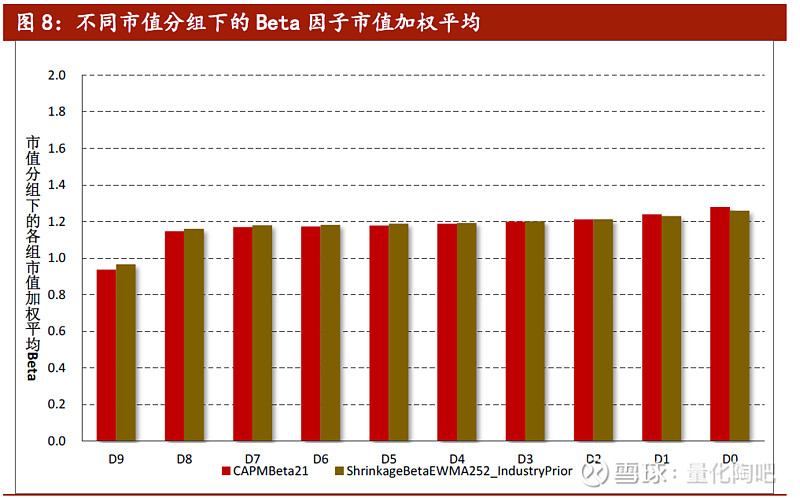
最后,我们观察不同市值分组下的各组Beta因子的市值加权平均值。可以看到,市值较大的组别(D9)组Beta因子较小,而市值最小的组别(D0组)Beta因子较大。可以认为,市值与Beta因子之间存在一定的相关关系,这也就是采用市值分组下的市值加权平均值作为其先验Beta的合理性所在。 4.6 小结 本小节我们从回望周期、加权方式、先验因子的选择三个方面对Beta因子的估计方式进行了实证检验。结论显示,采用过去1年的日度收益率数据,并经过EWMA加权,同时采用个股所在行业的行业均值作为先验因子进行压缩的方式,能够有效地改善Beta因子的预测能力。 总结与展望 5 作为最早的单因子定价系统——CAPM模型认为个股预期收益之间的差别取决于其承担的系统性风险大小,而系统性风险的大小可用Beta因子衡量。然而,由于Beta因子的估计本身涉及到较多参数,如何对参数进行选择才能够得到稳健的Beta估计值,业界现有的探讨却并不多见。本文我们从不同估计周期、加权方式、压缩方式三个方面出发,从实证角度介绍如何对Beta因子进行稳健估计。主要结论如下: (1) Beta因子的估计可以划分为等权情况下的CAPM Beta、EWMA加权情况下的CAPMBeta及压缩估计的Beta方法; (2) 关于估计误差的衡量,本文介绍了均方根误差RMSE、平均绝对误差MAE及Menchero(2016)方法; (3) 实证检验表明,采用过去1年的日度收益率数据,并经过EWMA加权,同时采用个股所在行业的行业均值作为先验因子进行压缩的方式,能够有效地改善Beta因子的预测能力。 风险提示 6 多因子模型拟合均基于历史数据,市场风格的变化将可能导致模型失效。 (附注:实习生上海财经大学硕士生程衍超全程参与本项研究,对本报告有重要贡献) 报告原文地址及相关报告 原始报告: 转载自研究报告:“星火”多因子系列(十):《如何对Beta因子进行稳健估计?》 下载地址: 链接:网页链接 提取码:kwg5 欢迎在Wind研报平台中搜索关键字“星火“和”拾穗”,下载阅读专题报告PDF版本 研究集锦: 【巡礼篇】一、二季度多因子系列专题汇总 【多因子量化选股研究集锦】2020,重新出发 “星火”系列专题报告: “星火”多因子系列(一):Barra模型初探:A股市场风格解析 “星火”多因子系列(二):Barra模型进阶:多因子模型风险预测 “星火”多因子系列(三):Barra模型深化:纯因子组合构建 “星火”多因子系列(四):基于持仓的基金业绩归因:始于Brinson,归于Barra “星火”多因子系列(五):源于动量,超越动量:特质动量因子全解析 “星火”多因子系列(六):Alpha因子重构:引入协方差矩阵的因子检验法 “星火”多因子系列(七):借助最小波动组合,助力Alpha因子合成 “星火”多因子系列(八):风险控制:协方差矩阵估计方法介绍及比较 “星火”多因子系列(九):博彩偏好还是风险补偿?高频特质偏度因子全解析 “拾穗”系列专题报告: “拾穗”多因子系列(一):带约束的加权最小二乘拟合:一种解析解法 “拾穗”多因子系列(二):你看到的不一定是你所想的:解密R方 “拾穗”多因子系列(三):行业因子选择:中信一级还是申万一级? “拾穗”多因子系列(四):总市值、流通市值、自由流通市值:谈谈取舍 “拾穗”多因子系列(五):数据异常值处理:比较与实践 “拾穗”多因子系列(六):因子缺失值处理:数以多为贵 “拾穗”多因子系列(七):从纯因子组合的角度看待多重共线性 “拾穗”多因子系列(八):非线性规模因子:A股市场存在中市值效应吗? “拾穗”多因子系列(九):牛市抢跑者:低Beta一定代表低风险吗? “拾穗”多因子系列(十):行业的风格偏好:解析纯行业因子组合 “拾穗”多因子系列(十一):多因子风险预测:从怎么做到为什么 “拾穗”多因子系列——期中总结 “拾穗”多因子系列(十二):权重复刻:指数成分股调整,股指期货分红点位测算更新 “拾穗”多因子系列(十三):恼人的显著性检验:多因子模型中t值的计算 “拾穗”多因子系列(十四):补充:基于特质动量因子的沪深300增强策略 “拾穗”多因子系列(十五):是聪明钱吗?探析外资持股的风格偏好 “拾穗”多因子系列(十六):水月镜花:正视财务数据的前向窥视问题 “拾穗”多因子系列(十七):因子检验中的时序相关性处理:Newey-West调整 “拾穗”多因子系列(十八):当我们在做因子正交化的时候,我们在做什么 “拾穗”多因子系列(十九):似是而非:时间序列回归VS横截面回归 |


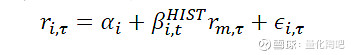



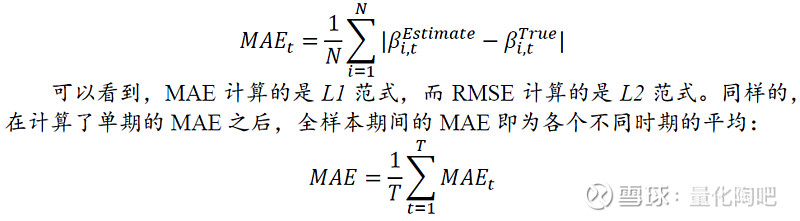



【本文地址】